材料
- 🎥 C5W3L03 Beam Search
- 🎥 C5W3L04 Refining Beam Search
- 🎥 C5W3L05 Error Analysis of Beam Search
- 📓 Beam Serach – OpenNMT
- 📚 Dive into DeepLearning – 9.8 Beam Search
- 🧾 Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
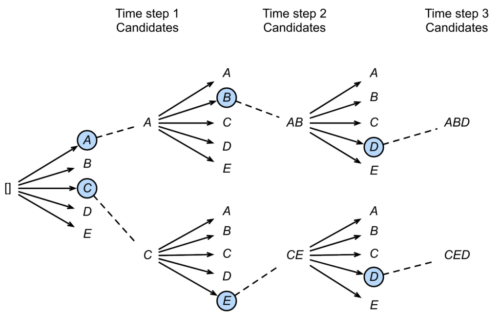
Beam Search 束搜索
Why
在序列预测的时候,如果我们每一步都使用argmax这种贪心的做法, 不能保证我们最终获取的序列整体是最优的. 比如这个最优的序列开始的几个分数并不高.
但是计算出所有可能的序列成本一般是不能接受的, 是一个NP-hard的问题. 特别是深度学习中每次预测其实计算消耗非常大. 所以Beam Search是一个折中的方案, 保留一个目前为止K个最好的子序列同时往下继续预测.
不能保证找到最好的答案,相比于贪心要好的多, 大概率可以找到不错的答案.
Unlike exact search algorithms like Breadth First Search or Depth First Search, Beam Search runs faster but is not guaranteed to find exact maximum probability result.
Beam Search的超参数就是K, K这个超参数一般可能的取值会在5~10之间. 这是一个在计算消耗和精度之间的平衡.
Score function 打分方法
Compare hypotheses of different length .
s(Y, X) = log(P(Y|X)) / lp(Y) + cp(X; Y)
ce a negative log-probability is added at each step.
Normalization 正则项
Length Normalization 长度正则
如果只使用log(P(Y|X))来计算分数, 这是联合概率分布的log值,本质上是一个连乘, 所以越短的句子往往越有概率获得一个更高的分数. 所以我们会对句子的长度进行正则, 惩罚特别短的句子.
Regular beam search will favor shorter results over longer ones on average since a negative log-probability is added at each step.
0< ɑ < 1 ,ɑ in [0.6 – 0.7] was usually found to be best.

Coverage Normalization 覆盖正则
希望attention模块能尽可能覆盖整个句子. 不要在个别词上投入太多的注意力权重.
Y is the predicts include all time steps.
pis the attention probability of the thejstep on inputi.
Favor the predict that full cover the sentence according to the attention module.

Error Analysis
Calculate the target sentence probability and compare with beam search result.
- If the target sentence probability > beam search result => beam search error
- Else : model error