摘要和介绍
multimodal model which can accept image and text inputs and produce text outputs.
只能输出文字,支持图片的输入,看来图片输出是下一个大事件。不过因为支持了图片的输入,所以在一些需要图片才能解决的题目或问题上就有了能力。
While less capable than humans in many real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers
能够在一些考试和专业的问题能够打平和超过人类专家。其实这个也不意外,GPT-4对于编程懂得比专业程序员多也不奇怪,所以也让我们知道,不要死记硬背,我们的竞争力不取决于死记硬背,要合理利用工具
A core component of this project was developing infrastructure and optimization methods that behave predictably across a wide range of scales. This allowed us to accurately predict some aspects of GPT-4’s performance based on models trained with no more than 1/1,000th the compute of GPT-4.
可以在很小的模型上进行训练和调参,就能预测在1000倍大的模型上的性能,这样调参起来方便,迭代就更快了,节约大量资源。从框架和方法上让训练大模型更有效,调参和迭代更快。
…., particularly in more complex and nuanced scenarios. To test its capabilities in such scenarios, GPT-4 was evaluated on a variety of exams originally designed for humans.
…
On a suite of traditional NLP benchmarks, GPT-4 outperforms both previous large language models and most state-of-the-art systems (which often have benchmark-specific training or hand-engineering).
GPT-4在人类的一些专业考试里,已经获得了大幅度提升,在一些专业考试中可以获得优异成绩;另外在传统的机器学习的benchmark中,不仅超过过去大模型的表现,还能够超过最好的专用模型(各种trick+微调的模型)。
Limitation
…it is not fully reliable (e.g. can suffer from “hallucinations”), has a limited context window, and does not learn from experience. Care should be taken when using the outputs of GPT-4, particularly in contexts where reliability is important.
可靠性和上下文长度是需要持续提升。
This report .. Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
没有技术细节,主要就是谈谈安全性,展示一下效果。OpenAI还真是变得一点也不Open。
Predictable Scaling
trained using the same methodology but using at most 10,000x less compute than GPT-4. This prediction was made shortly after the run started, without use of any partial results. The fitted scaling law predicted GPT-4’s final loss with high accuracy (Figure 1).
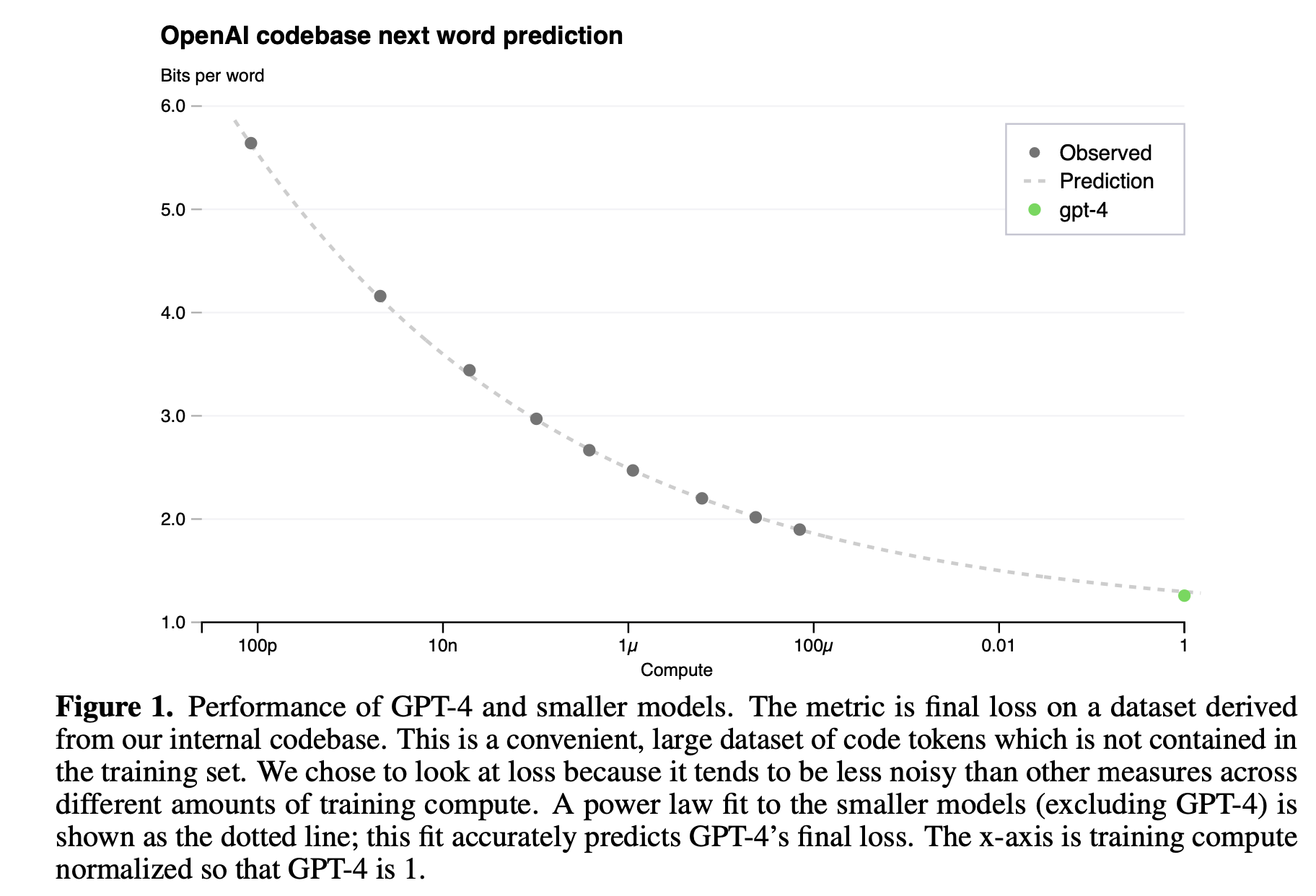
只有展示和说明能够在小几个数量级的训练并能够精准的预测在完整的GPT-4上的Loss
We successfully predicted the pass rate on a subset of the HumanEval dataset by extrapolating from models trained with at most 1, 000× less compute (Figure 2).
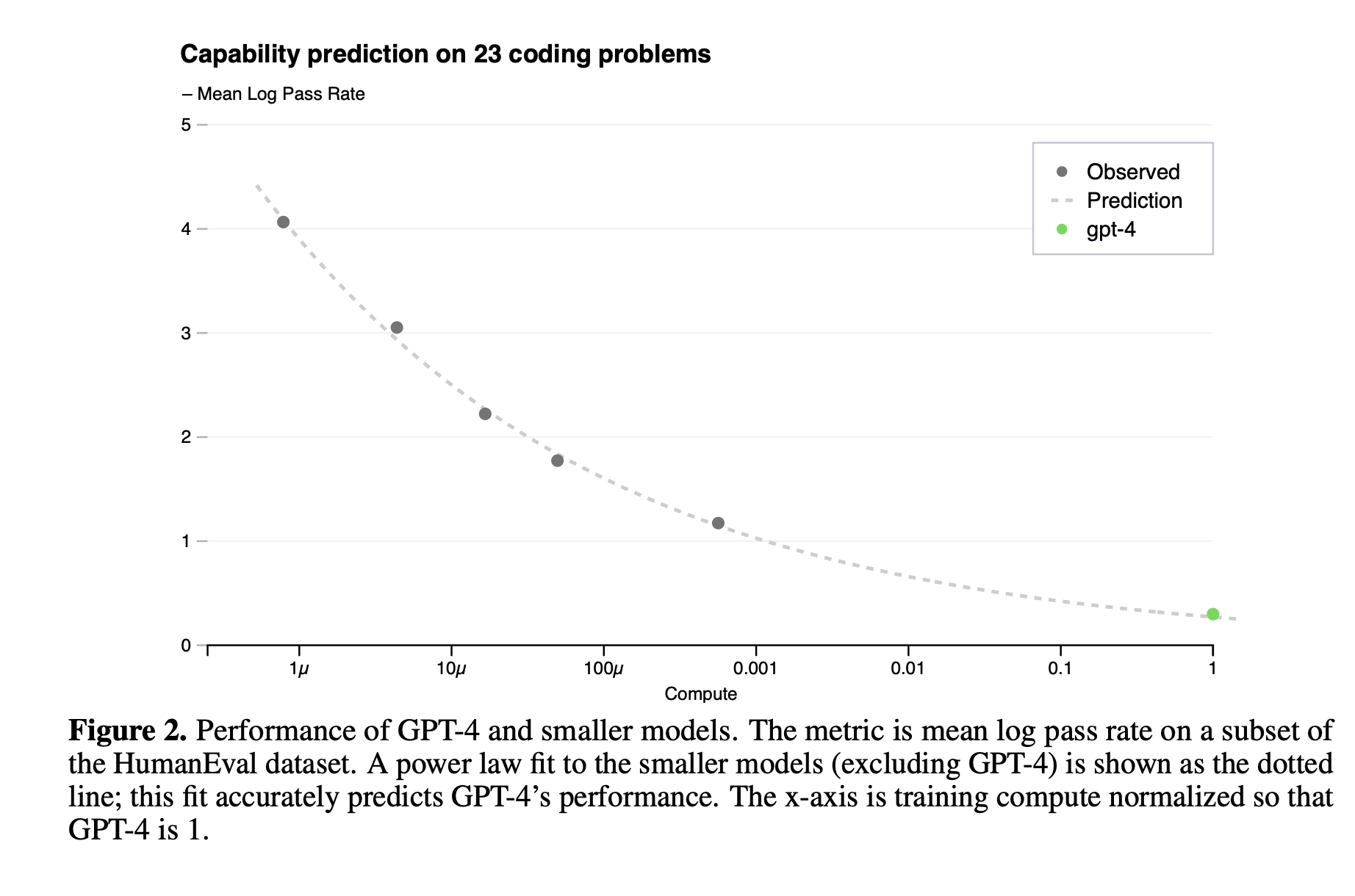
在人类问题验证数据集上也能做到比较精准的预测,不过有时候随着模型增大效果会不稳定。
Capabilities
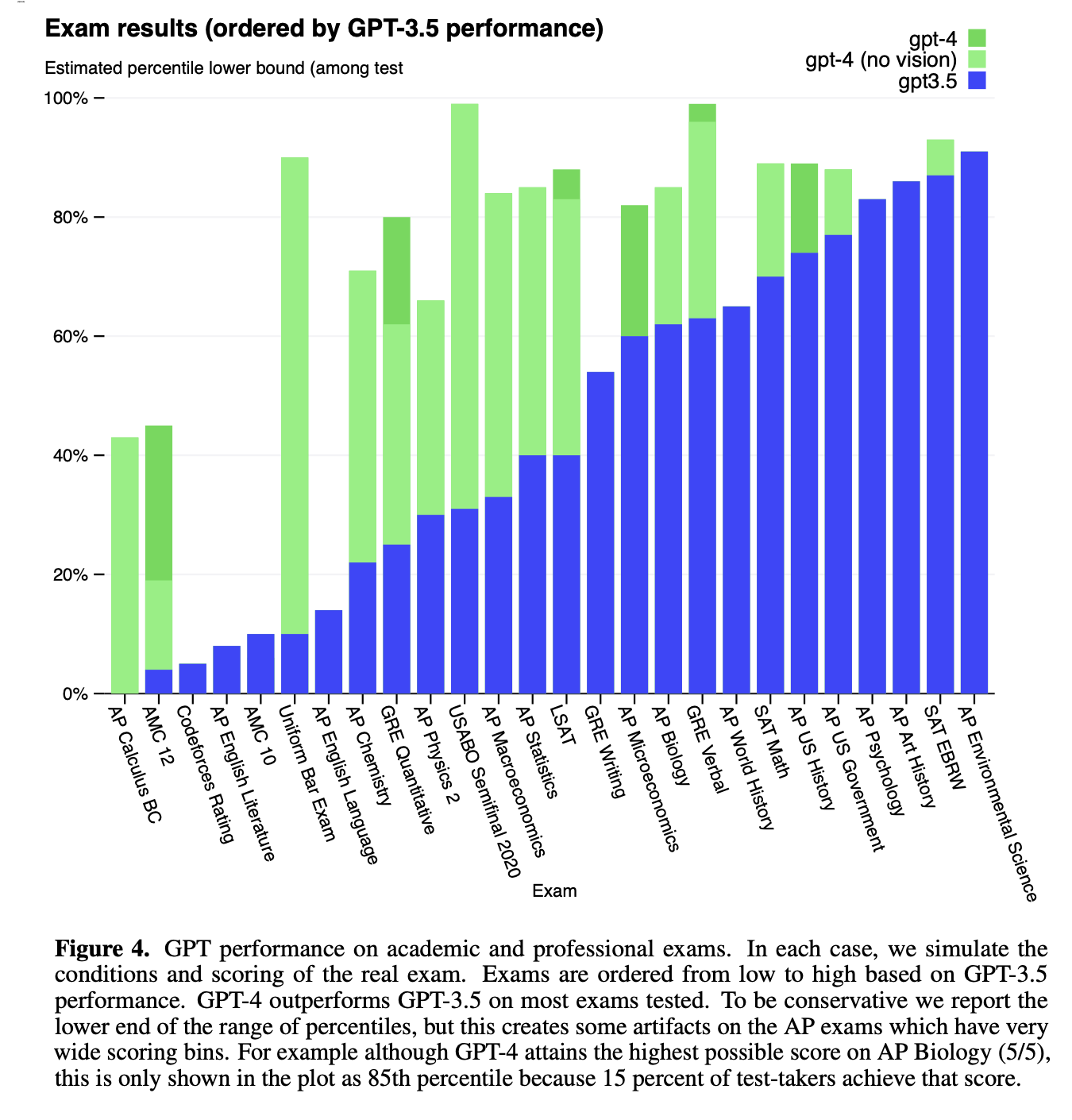
在各种模拟考试中,相比于之前的模型有了大幅度提升,有些考试有图片,所以添加图片信息后能够进一步提升分数
GPT-4 exhibits human-level performance on the majority of these professional and academic exams. Notably, it passes a simulated version of the Uniform Bar Examination with a score in the top 10% of test takers
在美国律师考试是很难而且很重要的,通过的人能够获得高薪工作机会。GPT-4能够获得前10%的成绩。所以一再强调这一点。
The model’s capabilities on exams appear to stem primarily from the pre-training process and are not significantly affected by RLHF. On multiple choice questions, both the base GPT-4 model and the RLHF model perform equally well on average across the exams we tested
没有特别对考试进行训练,测试发现即使这样做也没有非常明显的提升。就是说模型的学习和泛化能力足够强,而不是进行微调的结果。
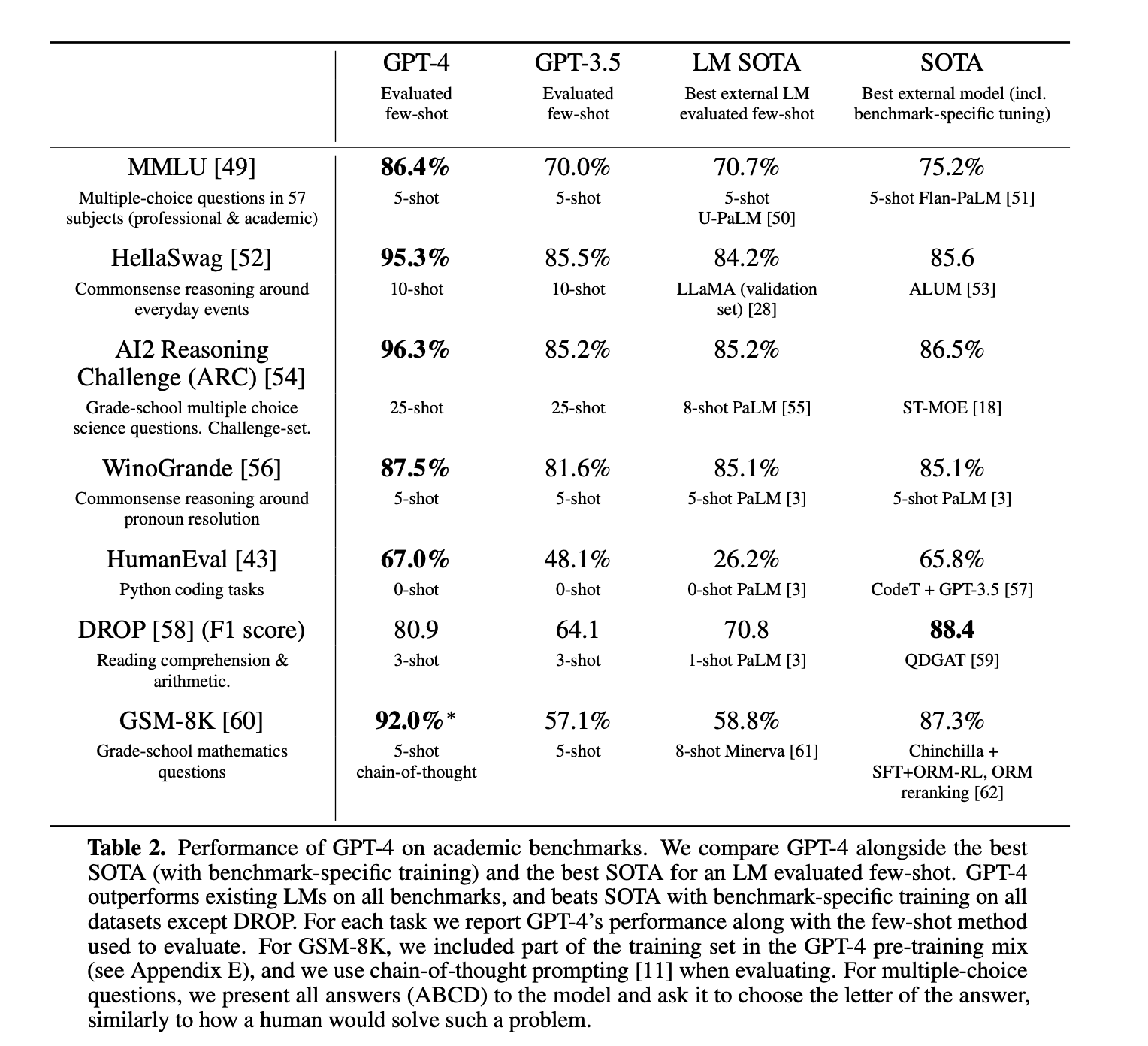
这里最大的成绩是能够大幅度领先之前针对具体问题进行设计和微调的SOTA模型,现在看来模型越来越走向大一统了,至少few-shot learning来进行标注、帮助训练或者直接使用有了更多的可能性。
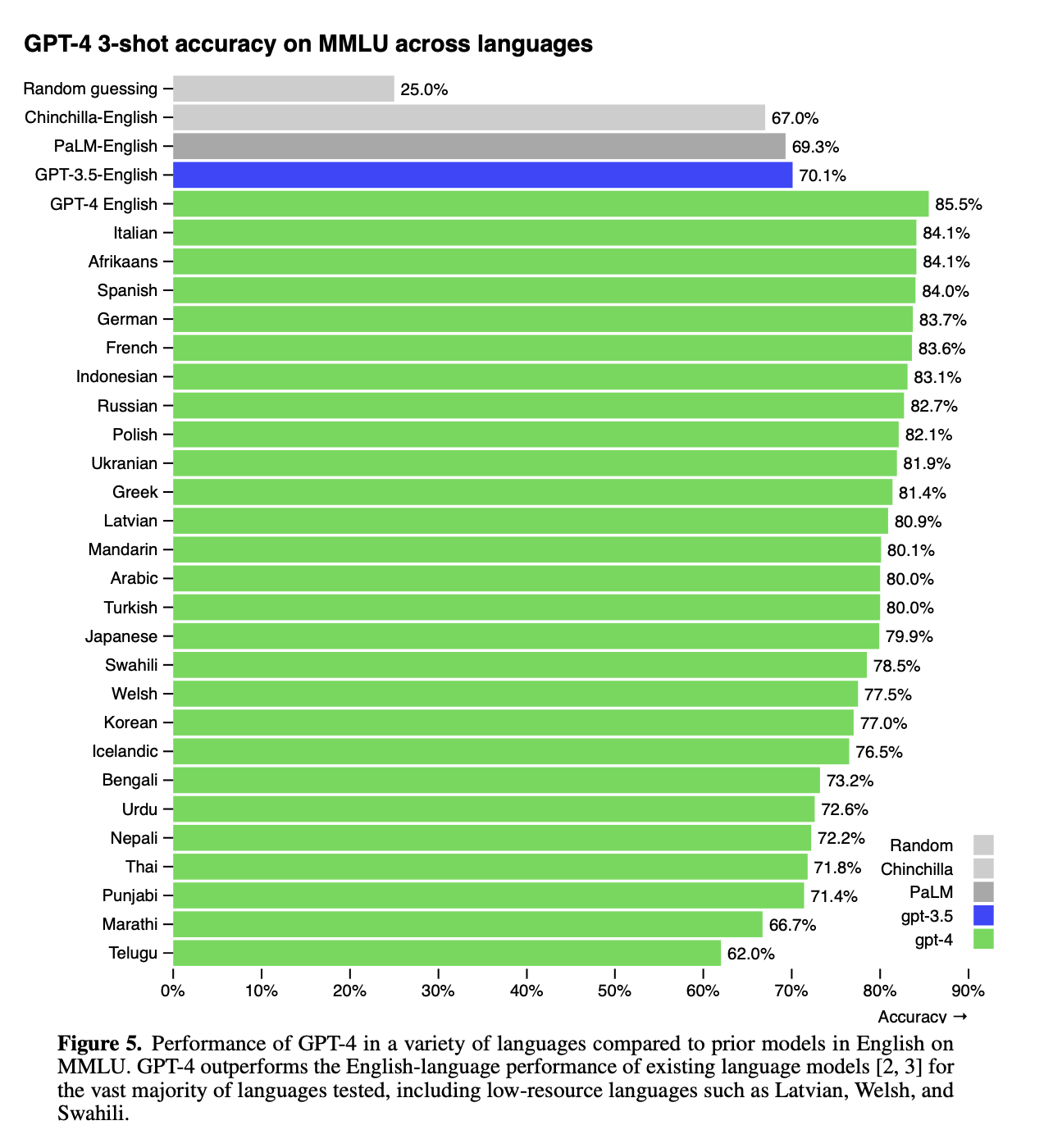
多语言能力非常强,即使一些非常少语料的语言也一样

GPT-4是支持图片的,现在都流行让模型解释图片为什么好笑。